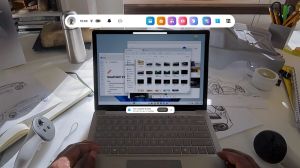
繁

你正坐在虚拟世界里的“月球表面”,伸手从空中抓取一罐3D建模的椰子水,轻轻放在桌边。下一秒,这瓶虚拟饮料开始“物质化”——光影流转,轮廓凝实。当你伸手去拿时,它已真实握在手中,冰凉触感从指尖传来。
这不是科幻电影,而是普林斯顿大学最新研究的实验现场。
在这个名为“Reality Promises”(现实承诺)的项目中,研究人员Mohamed Kari与Parastoo Abtahi构建了一套名为Skynet(与《终结者》同名,但无关联)的机器人控制系统,让一台佩戴VR头显的机器人,成为虚拟与现实之间的“物理信使”。
传统AR/VR的逻辑是:将数字内容叠加到现实世界。
而普林斯顿的实验,却走了一条“逆向路径”:
你在虚拟世界中“请求”一个物体 → 系统在现实世界中调度机器人取物 → 物体被精准送达你“预期”的物理位置 → 你伸手即得,沉浸感不被打破。
其核心技术闭环如下:
用户交互:佩戴Quest 3的用户在虚拟空间中“拾取”一个虚拟饮料模型;
空间锚定:用户将模型“放置”在现实桌面上的某个位置(通过MR透视对齐);
机器人调度:Skynet系统接收到“虚拟投放”指令,规划路径;
物理交付:机器人携带真实饮料,移动至目标位置,静默放置;
感知融合:用户看到虚拟饮料“完成加载”,伸手即触碰到真实物体。
整个过程,如同虚拟世界向现实世界“下单”,而机器人是那个“无声的快递员”。
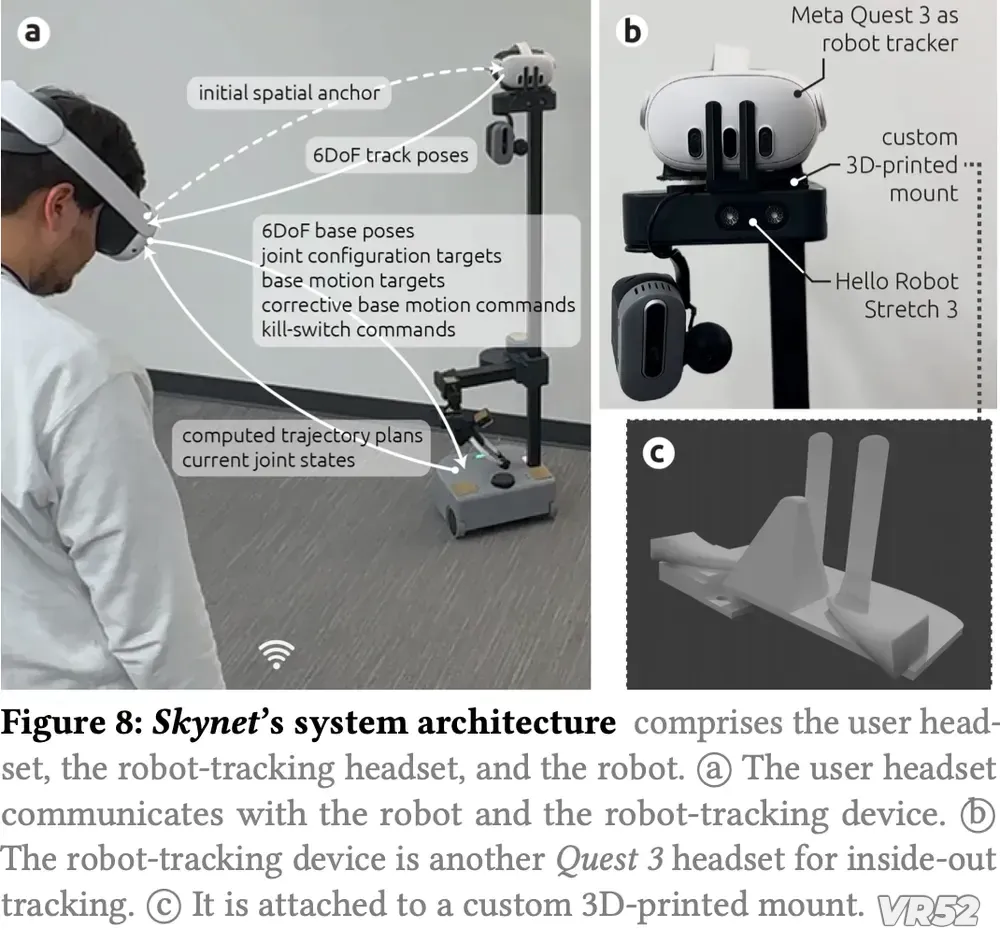
为了让沉浸感不被破坏,研究团队做了两项关键设计:
视觉抹除:机器人本身在VR画面中被“擦除”,用户只看到物体凭空出现,仿佛“量子传送”;
角色重绘:机器人可被“皮肤化”为虚拟世界中的某个角色——比如一个机械臂、一个浮空球,甚至一只赛博猫,让它成为虚拟叙事的一部分,而非突兀的“外来者”。
这不仅是技术实现,更是人机交互哲学的跃迁:
技术不应强行闯入体验,而应无缝融入用户的认知预期。
最令人玩味的设计是:机器人自己也戴着VR头显。
原因在于——它需要“看见”同一个虚拟空间。
通过共享VR坐标系,机器人能精确理解:
用户在虚拟世界中“放”饮料的位置;
该位置对应现实空间的哪一点;
周围是否有障碍物(虚拟标注);
是否需要避让“虚拟家具”。
这相当于为机器人提供了一套语义增强的地图,远超传统SLAM的几何感知能力。
这项研究发表于ACM UIST(人机交互顶级会议),与另一项“代理(proxies)”研究共同指向一个未来:
VR/MR头显不应只是“显示器”,而应成为控制物理世界的“中枢”。
“Reality Promises”这一概念,本质上是一种跨现实的用户界面协议:
你“承诺”一个虚拟动作;
系统“承诺”一个物理结果;
机器人是兑现承诺的“执行单元”。
它解决了长期困扰空间计算的核心问题:
虚拟世界再丰富,也无法解渴。




VR52网成立于2015年,平台提供VR头显、AR眼镜、配件外设、厂商、测评、行业资讯、游戏与应用、展会活动等。