繁
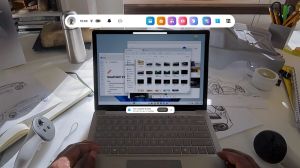
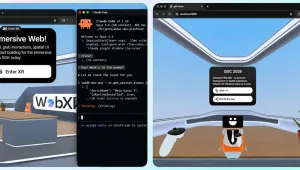
Meta近日宣布对其开源沉浸式网页SDK(IWSDK)进行重大更新。该框架基于WebXR标准,旨在帮助开发者在网页端构建VR体验。此次更新的核心,在于引入了由AI编码助手驱动的"智能体工作流"(AgenticWorkflow)。从"辅助生成"到"闭环开发"IWSDK最早于去年的MetaConnect大会上推出,初衷是将物理系统、手部追踪、抓取交互及空间UI等复杂的底层工程问题模块化,让创作者能更专注于创意实现。而新加入的智能体工作流,则进一步集成了ClaudeCode、Cursor、GitHubCopilot及Codex等主流AI编码工具。Meta在开发者博客中明确指出,智能体工作流的意义在于AI不再仅仅局限于生成代码片段,而是能进行自动化测试与验证。这种"生成-测试-验证"的闭环系统,被认为是保障高质量、高可靠性产出的关键。IWSDK的这一集成试图将闭环完全打通,以最大化开发者的生产效率。15小时复刻数万行代码:实证生产力跃迁为演示该系统的实际效能,Meta团队重新构建了其2022年的VR园艺演示项目"ProjectFlowerbed"。原项目由数万行自定义代码构成,而在使用IWSDK的AI工作流及原有美术资源后,整个可交互的Web端VR应用仅耗时15小时便完成了重建。Meta强调,这并非简单的修修补补或生成样板代码,而是一次由AI主导、基于IWSDK的完整重建。WebXR的天然优势:即点即玩与低门槛Meta大力推动IWSDK与AI结合的背后逻辑,核心在于网页端VR(WebXR)的部署便利性。不同于传统VR开发漫长的编译等待,WebXR内容可在浏览器中即时测试,并通过简单URL跨桌面和VR头显分发,省去了应用商店审核与安装包下载的繁琐。值得注意的是,Meta透露仅Quest平台每月已有超100万用户访问WebXR内容,这也成为其持续加码网页端VR生态的重要支点。目前,IWSDK项目已基于MIT许可开源,开发者可通过GitHub进一步了解或体验这一全新的AI工作流。SDK:https://iwsdk.dev/ github:https://github.com/facebook/immersive-web-sdk
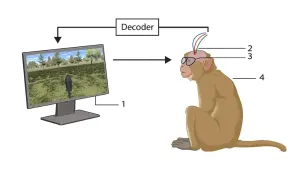
近日,据《新科学家》(NewScientist)报道,比利时鲁汶大学(KULeuven)的研究团队在脑机接口(BCI)领域取得了一项引人注目的进展:他们成功让恒河猴仅通过大脑活动,就能在复杂的3D虚拟环境中进行直观导航和互动,且所需训练量远低于以往技术。研究方法与核心创新该研究由PeterJanssen领导。研究团队为三只恒河猴植入了包含96个电极的"犹他阵列"(Utaharray)脑机接口设备,但其关键创新并非硬件本身,而在于信号解码的新方法。电极被精准植入三个与运动控制相关的大脑区域:初级运动皮层(PrimaryMotorCortex):负责执行具体的自主运动。背侧与腹侧前运动皮层(Dorsal&VentralPremotorCortices):主要负责运动的规划、组织与发起。Janssen认为,这种对运动规划区域而非单纯执行区域的读取,建立了一种更"直观"的连接。猴子们只需经过一次简短的被动观察阶段后,便能戴上3D快门眼镜,在屏幕上操控虚拟物体,包括一个球体、一个猴子虚拟化身,甚至以第一人称视角移动自己。为何这项技术更具"直觉性"?传统的BCI人体试验通常要求受试者主动想象一个具体的肢体动作(例如"动手指"),系统再将此信号转化为屏幕上的光标移动。Janssen向《新科学家》表示,这种方法对使用者来说感觉非常"陌生","就像试图用耳朵去移动东西一样"。而他们的新方法,似乎是直接读取了大脑中关于"想要去哪里"或"想要做什么"的更高层次意图,从而绕过了对具体肌肉动作的模拟,大幅降低了学习成本。未来展望:从轮椅到虚拟世界这项研究为未来的临床应用铺平了道路。Janssen指出,该技术有望帮助瘫痪患者更直观地控制电动轮椅,或让他们在虚拟世界中自由漫游,极大地提升生活质量和社交参与度。当然,从猴子到人类还有很长的路要走。Janssen坦言:"我们还需要做大量工作来精确确定在人类大脑中的最佳植入位置,因为这些区域在人类身上的确切位置尚不十分明确。但一旦我们搞清楚了,这应该是可行的,甚至会更容易,因为我们能直接告诉人类受试者该怎么做。"
当前的虚拟现实技术主要聚焦于视觉、听觉,辅以有限的触觉反馈,而人类的其他感官,尤其是嗅觉,则长期处于空白状态。如今,一支由四位独立研究者组成的团队,提出了一种无需消耗性香精cartridges的革命性方案--利用经颅聚焦超声波(tFUS)直接刺激大脑中的嗅觉中枢。为何嗅觉对VR至关重要?科学家称嗅觉为"最原始的感官"。与其他感官不同,嗅觉神经不经过大脑皮层的高级处理,而是直接连接到边缘系统,该区域掌管着情绪与记忆(如海马体)。这正是为何气味能瞬间、强烈地唤起尘封已久的记忆。有观点认为,即使未来VR能通过"视觉图灵测试",只要用户闻到的仍是现实房间的气味,其潜意识就无法真正相信自己身处虚拟世界。过往尝试为何失败?历史上,从1950年代的"Smell-O-Vision"到2016年VR热潮催生的Feelreal、Vaqso等初创公司,都试图通过向用户鼻腔喷射化学香精来模拟气味。然而,这种方法存在致命缺陷:法规风险:被归入电子烟等严格监管范畴;成本高昂:需持续购买替换香精盒;体验局限:可模拟气味种类有限,且气味残留时间不可控。这些因素共同导致了所有相关产品的商业失败。革命性突破:绕过鼻子,直击大脑这支名为LevChizhov(神经科技创业者)、AlbertYan-Huang(加州理工学院研究员)、ThomasRibeiro与AayushGupta(软件与AI专家)的团队,另辟蹊径,完全绕开了鼻腔。他们的设备通过佩戴在前额的超声波发射器,将低频超声波穿透颅骨,精准聚焦于深藏在鼻梁后方的嗅觉球(olfactorybulb)。为解决超声波在空气中传播不佳及鼻部曲面难以贴合的问题,他们设计了一个果冻状的固体耦合垫置于前额,并通过MRI扫描确定了最佳发射参数:频率:300kHz(足够低以良好穿透颅骨)焦深:约39毫米偏转角:50–55°(向下指向嗅觉球)脉冲模式:5周期脉冲,1200Hz重复频率实验成果:成功诱导多种气味感知在实验中,研究人员成功诱导出多种主观嗅觉体验,包括:清新空气("富含氧气的感觉")腐烂垃圾("像放了几天的水果皮")臭氧味("如同站在空气净化器旁")篝火("燃烧木头的气味")他们区分了两种感知:"气味"(smell)感觉强烈且有明确来源方向,仿佛可以"嗅探"到源头;而"感觉"则更为弥散,常伴有轻微的面部麻刺感(可能是安慰剂效应)。所有感知在轻柔吸气时最为明显。"当Albert第一次闻到'垃圾味'时,他猛地睁开眼睛,以为真的有垃圾车开进了房间!"从VR到脑机接口:更宏大的未来尽管目前的原型机仍需双手持握,但其小型化潜力巨大。更重要的是,这项技术的意义远超VR。当前的脑机接口(BCI)多为"读取"大脑信号,而此方法则是非侵入式地向大脑"写入"信息,触及了科幻领域的核心概念。研究者虽承认这仍是"推测性的",但鉴于嗅觉球与大脑关键区域的直接连接,未来或能实现更复杂的感官乃至认知干预。短期内,虽然消费级产品集成此技术尚不现实,但企业级高端头显制造商很可能在未来几年内率先探索这一方向。一场真正的感官沉浸革命,或许已经拉开序幕。
2026年4月8日,Meta宣布为其开源网页VR框架ImmersiveWebSDK(IWSDK)新增一套革命性的AI智能体集成开发工作流。开发者现在只需用自然语言描述创意,AI即可自动完成从代码生成、运行测试到错误修复的全过程,真正实现"所想即所得"的VR内容创作。IWSDK:为复杂VR功能提供开箱即用的解决方案IWSDK最初在2025年的MetaConnect大会上亮相,旨在解决Web端VR开发中的核心难题。该框架已内置对物理引擎、手部追踪、抓取交互、空间化UI等复杂功能的支持,让开发者能将精力集中在创意本身,而非底层技术实现。AI智能体工作流:从想法到可运行体验的全自动闭环此次更新的核心是深度集成的AI工作流。其运作方式如下:自然语言输入:开发者在支持的AI编码工具(如ClaudeCode、Cursor、GitHubCopilot等)中打开IWSDK项目,并用自然语言描述想要构建的VR场景或交互。智能代码生成:AI不仅会生成代码,还会主动截取VR场景的屏幕截图,分析其中物体的位置与相互关系,以此为基础生成更精准的代码。自主测试与迭代:AI会自动运行生成的VR体验,检测是否存在逻辑或视觉问题。一旦发现问题,它会立即进行修正,并不断重复"生成-测试-修复"的循环,直至体验完美。自然语言反馈:开发者甚至可以用"动作太快了"或"这个物体应该更大一点"等直观的自然语言指令来指导AI进行优化。实测效果惊人:数万行代码项目15小时重建为验证该工作流的效率,Meta团队选择了一个极具挑战性的任务:从零开始重建其现有的WebVR应用"ProjectFlowerbed"。该项目原本包含数万行高度定制化的代码,而借助新的AI工作流,整个重建过程仅耗时15小时,充分展现了其强大的生产力。快速上手,无需头显该工作流对硬件要求极低,大大降低了VR开发门槛:所需环境:Node.js20+、Chrome或Edge浏览器,以及任意一款支持的AI编码工具。启动命令:在终端执行npmcreate@iwsdk即可创建新项目。无头显开发:整个开发和测试过程均可在普通电脑上完成,无需佩戴VR头显。当然,Meta也推荐使用Quest3、3S或Pro进行最终的沉浸式实机测试。IWSDK以MIT许可证开源,所有开发者均可免费使用和贡献。更多详情请访问官方站点iwsdk.dev。
3月25日,谷歌研究(GoogleResearch)发布了"VibeCodingXR",这是一种通过"氛围编程"即时构建复杂XR应用的工作流。"氛围编程"(VibeCoding)是一种只需向AI传达需求或想法的"氛围"(Vibe),即可生成程序代码的方法。由于无需专业知识也能创建应用或网络服务,它正开始在AI领域普及。此外,与传统的编码方法相比,它能大幅提高开发速度。然而,虽然短期内构建软件的速度很快,但在大型项目中,一旦代码变得复杂,就可能出现与规格不符或产生漏洞的风险。特别是在XR领域,由于需要手部追踪等空间识别技术以及与复杂游戏引擎的兼容,准入门槛依然很高,这成为了阻碍其普及的因素。此次发布的"VibeCodingXR",通过结合谷歌的AI"Gemini"和开源的WebXR框架"XRBlocks",实现了即时构建复杂XR应用的工作流。"XRBlocks"将XR的复杂处理(如手部动作识别、物理运算、空间把握等)抽象化为模块,再借助"Gemini"强大的推理能力像拼图一样将它们组合起来,使得即使在氛围编程中也能生成错误率更低的代码。以下介绍"VibeCodingXR"的部分应用实例。薛定谔的猫,一款解释量子概念的XR应用程序此外,该项目还对AI生成应用的准确度进行了量化"技术评估"。评估使用了从谷歌内部收集的60个课题,从生成的"速度"和"准确性"两个维度进行评价。结果显示,使用高性能模型"GeminiPro"时,几乎能一次性(95%左右)成功生成无错误的应用。而高速版"GeminiFlash"则创下了仅用约20秒的惊人速度。开发初期,由于API误识别等原因,成功率仅停留在70%左右,但经过半年内11次改进,已进化到实用水平。此次发布的"VibeCodingXR",迈出了"XR领域氛围编程"实用化的第一步。目前,谷歌正致力于搭载AI的"AndroidXR"新设备的开发和更新,预计未来"VibeCodingXR"也会以某种形式被整合并加以利用。
增强现实技术开发商NianticSpatial今日正式宣布推出Scaniverse。这是一个集网页端与移动端于一体的平台,专门用于捕捉物理空间并生成空间资产。与此同时,公司还发布了其更新版的视觉定位系统VPS2.0。什么是Scaniverse?Niantic将Scaniverse描述为其空间智能服务和大型地理空间模型的"门户"。它能让用户捕捉3D空间,并生成视觉定位地图、网格(meshes)和高斯泼溅(Gaussiansplats)。适用范围:该平台支持从单个房间到数千平方米区域的空间捕捉。兼容设备:支持包括消费级智能手机和360°全景相机在内的多种设备。未来计划:公司表示,今年晚些时候计划增加对更多数据捕捉类型和格式的支持。移动端功能更新后的Scaniverse应用程序允许用户通过单次扫描或在查看器中合并多次扫描来生成视觉定位地图、网格和泼溅图。协作与云端:多位用户可以在不同时间和设备上为同一个共享项目贡献扫描数据。上传的数据会存储在云端,并随着新扫描的加入融合成单一模型。现场预览:应用程序包含设备端的VPS地图预览功能,允许用户在现场(包括低网络连接环境)进行覆盖范围和质量检查。用户体验:现有Scaniverse用户的使用体验保持不变。网页端功能网页版Scaniverse提供了一个基于浏览器的门户,用于上传、管理和处理来自移动应用及360°相机的数据,并在查看器中可视化输出结果。数据处理:用户可以上传360°相机footage以重建大面积区域的高斯泼溅图,并生成和预览用于NianticSpatialVPS的网格、泼溅图和位置地图。即将支持:对360°相机footage的VPS支持即将推出。导出格式:资产可以导出为FBX、PLY和SPZ格式。据NianticSpatial称,文件还可以转换并导入到机器人模拟器中。什么是NianticSpatial的VPS2.0?伴随Scaniverse一同发布的还有VPS2.0,这是一个可在全球范围内运行的更新版视觉定位系统。超高精度:NianticSpatial表示,在通过Scaniverse映射的区域,VPS能提供接近厘米级精度的6DoF(六自由度)定位。相比之下,GPS在理想条件下的精度约为3-5米。无需预扫描:VPS2.0消除了对地点进行预扫描的需求,并能增强GPS以提供3DoF定位。抗干扰能力:该系统利用视觉上下文和多种数据源来修正GPS漂移和信号丢失,从而在GPS信号可能较弱的环境中提供稳定、一致的位置信息。最终结果是一个统一的系统:它首先通过全球VPS提供更广泛的可靠定位,然后在进入Scaniverse映射的区域时,无缝切换到接近厘米级精度的6DoF定位。目标行业与应用Niantic指出,Scaniverse和VPS专为以下领域设计:机器人OEM厂商和运营商:用于在室内或GPS信号弱、难以维持位置的机器人。能源、建筑和物流:将复杂的站点映射为团队和机器共享的空间模型。公共部门:用于GPS信号可能减弱或不可用,需要更可靠位置和航向数据的环境。大型场馆:用于持久化、位置感知的空间应用。此外,公司还宣布NSDK4.0将于本月正式向公众开放,支持Swift、Unity、原生Android,并可应要求提供对ROS2的早期支持,从而将开发者直接连接到Scaniverse和VPS2.0。
近日,非营利性行业联盟KhronosGroup宣布推出高斯泼溅技术的glTF格式扩展方案,并已进入发布候选阶段。此举旨在将这一新兴的3D图形表示方法纳入当前最主流的3D资产传输标准,为跨平台、跨设备的沉浸式内容分发铺平道路。KhronosGroup是OpenGL、Vulkan、WebGL等图形API的管理者,同时也是XR领域开放标准OpenXR的发起者。OpenXR已被Meta、Valve、HTC、字节跳动、EpicGames、Unity、NVIDIA和高通等主流厂商广泛采用--唯独苹果坚持使用自家私有接口。glTF:3D世界的"JPEG"2015年,Khronos推出了glTF(GraphicsLanguageTransmissionFormat),被业界誉为"3D领域的JPEG"。该格式专为高效传输与加载3D场景和模型而设计,支持从任意创作工具导出高质量资产,并确保在各类设备或网页浏览器中即时、一致地呈现。如今,glTF已成为Web端事实上的3D标准。高斯泼溅技术近年来在XR领域崭露头角:用户仅需用智能手机环绕拍摄,即可快速生成具备照片级真实感的3D环境或物体模型,并在VR中自由探索。Meta的Hyperscape、苹果改进后的Personas、Gracia的体素场景,以及Marble的AI生成3D环境,均已采用该技术。然而,捕捉容易,分享困难--这正是阻碍高斯泼溅走向大众的核心瓶颈。Khronos此次推出的glTF扩展,正是为解决这一问题:它允许将高斯泼溅数据直接嵌入glTF文件中,借助现有生态实现标准化交付。"Instagram让照片分享变得简单,TikTok引爆了短视频社交。而3D内容一直落后,因为建模和分享太复杂。"Khronos主席NeilTrevett表示,"高斯泼溅让普通用户用手机就能快速生成3D模型,而作为开放标准的glTF则让这些模型可以像图片一样轻松分享--甚至在社交媒体上实现全交互式展示。"为何标准化如此关键?高斯泼溅并非传统基于网格的3D建模方式。它将场景视为密集的体素点云,每个"泼溅点"包含位置、尺度、旋转、颜色和透明度等属性。相比多边形网格,它能更真实地还原头发、烟雾等复杂几何结构,以及反射、折射等高级光照效果。但若缺乏统一格式,各平台可能各自为政,导致生态割裂。正如专注高斯泼溅技术的媒体RadianceFields主编MichaelRubloff所言:"当行业从2D向3D迁移时,基于glTF这样的通用格式构建基础,能有效避免碎片化,让开发者确信今天构建的内容未来可跨平台部署,而非被锁定在单一生态中。"仍在演进:标准尚未最终定型目前,该glTF扩展仍处于发布候选阶段,Khronos3D格式工作组正邀请引擎开发者、创作者和艺术家参与测试,目标是在2026年第二季度完成正式批准。值得注意的是,当前版本尚未定义标准压缩方案--这对移动端性能至关重要。为保持技术前瞻性,规范设计为可扩展架构,为未来算法演进预留空间。包括Autodesk、BentleySystems、华为、NianticSpatial和NVIDIA在内的多家企业已参与该扩展的开发,显示出产业界对高斯泼溅标准化的高度重视。
2025年1月21日,WorldLabs宣布推出一款名为WorldAPI的创新接口,允许用户通过其先进的多模态世界模型"Marble"生成并构建可探索的3D虚拟环境。该平台自2025年11月公开以来,因其能够从文本、图像、视频及全景照片等多种输入源生成高度逼真的3D世界而广受赞誉。Marble的核心能力:从素材到虚拟空间的无缝转换"Marble"具备以下关键特性:支持多种输入格式:无论是实景拍摄的照片、视频还是纯文本描述,都能转化为可供用户自由漫游的虚拟空间;智能解析与整合:自动分析输入素材的布局和结构,并将生成的数据无缝集成至网页浏览器或专业制作工具中;高度编辑性:用户可以轻松调整材质质感、删除不必要物体、修正区域边界,甚至为场景增添细节或连接多个空间。此外,WorldAPI还支持以GaussianSplatting(高斯泼溅)和Mesh两种格式输出3D模型,确保与主流游戏引擎及其他标准制作工具的兼容性。应用广泛:从游戏到建筑,再到机器人模拟WorldAPI不仅限于娱乐领域,其应用场景覆盖了多个行业:游戏开发:通过摄像头操作实时生成动态视频,模拟火焰、水流等复杂效果;建筑设计:助力设计师将草图快速转化为三维可视化成果,加速设计流程;机器人仿真:已被NVIDIA等知名公司采用,在机器人训练与测试环境中发挥重要作用;沉浸式体验:如Escape.ai仅凭20张图片即可创建出引人入胜的虚拟环境。强大的技术背景与资金支持WorldLabs由著名AI研究者李飞飞博士创立,并已获得来自顶尖投资机构的总计2.3亿美元融资。这一雄厚的资金基础为其技术研发提供了坚实保障,推动着WorldAPI不断拓展其在各领域的应用潜力。项目地址:https://www.worldlabs.ai/blog/announcing-the-world-api
从一次童年误操作说起:为什么"安全卸载"如此重要?在去年SteamFrame发布前夕,一位科技作者在Valve总部体验设备时,回忆起自己1995年左右的一次"系统灾难":年仅十岁,他将父亲带回家的办公电脑中的游戏文件直接拖入回收站清空,结果导致整台机器只能以安全模式启动。面对父亲即将下班的倒计时,恐惧与泪水交织--这成为他对"封闭系统脆弱性"的第一课。三十年后,当这位作者试图向自己的青少年子女解释Mac与SteamDeck之间的差异时,真正难以传达的并非技术细节,而是更深层的理念:为什么"开放"和"离线计算"在今天依然至关重要?Valve工程师对此给出了清晰回应:SteamDeck提供两种使用层级。用户若希望修改系统文件,可开启读写模式;但对大多数只想安装应用的普通用户而言,Flatpak格式提供了类似AndroidAPK的沙盒化体验--应用自包含、运行隔离、卸载后系统状态完全复原,确保不会因误操作导致系统崩溃。这种设计,正是为了规避早期Windows时代常见的"删游戏变砖机"风险。Flatpak之于Linux桌面,正如APK之于Android:两者虽面向不同平台,但核心理念一致--构建一个既易用又安全的应用分发机制。开放的Linux桌面:SteamFrame不只是游戏机如今,许多青少年接触的第一台"计算机"往往是iPhone、iPad或学校配发的Chromebook。这些设备高度依赖在线账户,由家长或教育机构严格管控,功能边界清晰,探索空间有限。相比之下,SteamFrame提供了一种截然不同的入口:戴上XR头显后,无需登录任何账户,即可直接进入基于Linux的完整桌面环境。用户可通过语音浏览器自由访问开放网络,安装第三方软件,甚至进行系统级调试--整个过程不依赖云端验证或平台许可。据体验者反馈,其预期在SteamFrame上首日即可通过Flathub(常被称作"Linux应用商店")安装VLC、Discord、RetroArch、Spotify等常用工具。这种开箱即用的扩展能力,远超其在AndroidXR设备上数日的折腾成果,甚至优于多年使用MetaQuest或AppleVisionPro的累积体验。值得注意的是,这种自由并非无代价--用户完全可能因过度修改导致系统异常,需手动恢复出厂设置。但恰恰是这种"可破坏、可重建"的特性,还原了1990年代PC黄金时代的探索精神:设备既是家电,也是游乐场。2026年1月Flathub上的热门应用。Valve的长期主义:十年开源投入,只为让游戏更好玩Valve对开放生态的坚持并非临时起意。过去十余年,公司持续资助全球匿名开发者推进一系列关键开源项目,逐步构建起SteamOS的技术底座。据Valve代表介绍,当前SteamFrame所呈现的体验--从操作系统内核(基于ArchLinux)、桌面环境(KDEPlasma)、图形驱动到Proton兼容层--几乎全部建立在开源基础之上。其中,Plasma团队甚至曾获得Valve直接资金支持,专为游戏场景优化交互与性能。更关键的是,Valve始终相信:平台的核心价值不应由单一公司定义,而应由社区横向共创。"如果所有优质体验都必须经过平台审核,多样性将被扼杀。"一位工程师指出,"用户之间自发分享模组、配置、工具链--这种生态只有在开放系统中才能繁荣。"因此,Valve刻意避免扮演"体验守门人",转而提供基础设施,让社区自主演进。这一理念深植于公司基因。《反恐精英》《DOTA》等现象级作品最初均源自玩家模组;免费游戏、MOBA等品类亦诞生于PC开放生态。相较之下,封闭平台往往将创新"冻结"在特定形态,而PC(以及如今的SteamVR)则因开放性持续迭代。"我们不是在发明新范式,"Valve方面强调,"只是将PC数十年来的开放精神,自然延伸至VR领域。"
只需输入一段文字或一张图片,就能即时生成一个完整、连贯且可自由漫游的3D虚拟空间--这正是AI初创公司SpAItialAI最新推出的生成式模型Echo所实现的能力。该技术不仅大幅降低3D内容创作门槛,更重新定义了人与虚拟空间的交互方式。真正的"空间生成",而非像素拼接Echo背后的核心技术是一种被称为空间基底模型(SpatialFoundationModel,SFM)的新型AI架构。与传统生成模型聚焦于像素不同,SFM直接以物理空间本身为生成对象。它能基于现实世界的物理规律,在米级尺度上预测完整的3D场景结构,确保新视角、深度图及交互结果均源自同一个一致的底层世界模型。这意味着,无论用户从哪个角度观察或如何操作环境,所见内容都具备几何与语义上的一致性,避免了传统方法常见的视角断裂或逻辑矛盾问题。实时交互+低门槛访问,人人皆可创作3DEcho生成的3D世界支持实时相机控制与即时渲染,即使在普通笔记本电脑或低性能设备上,也能通过网页浏览器流畅运行,无需高端显卡或专业VR设备。这种轻量化设计使其覆盖人群从专业设计师延伸至普通消费者。更关键的是,Echo并非"一次性输出"。用户可在生成后对3D场景进行深度编辑:更换材质、增删物体、整体风格重绘等操作均可实现,且系统会自动维持场景的三维一致性,确保修改后的世界依然逻辑自洽、视觉连贯。应用场景广阔,从游戏到机器人仿真凭借上述特性,Echo为多个领域打开了新的工作流可能:数字孪生:快速构建真实环境的可交互复刻;游戏开发:一键生成基础关卡并支持后续迭代;3D设计与建筑可视化:从草图或描述直接进入空间体验;机器人训练:在符合物理规律的合成环境中进行仿真学习。目前,SpAItialAI已在其官网展示多个由Echo生成的示例世界,并开放封闭测试注册通道。用户仅需提供一段文本或单张图像,即可尝试构建属于自己的可编辑3D宇宙。体验申请:https://www.spaitial.ai/join-waitlist
Apple机器学习研究团队近日公开了一项名为SHARP(Single-imageHolisticAndRealisticPhotorealism)的全新3D合成技术。该方法仅需一张普通照片,即可在不到一秒的时间内生成具备真实感的3D场景,并支持实时渲染--为单图像3D重建领域树立了新的性能与质量标杆。秒级推理+实时渲染,效率提升千倍SHARP的核心技术在于,通过一个端到端的神经网络,直接从单张输入图像中预测出3D高斯表示(3DGaussianrepresentation)的完整参数。整个过程仅需一次前向推理,在标准GPU上耗时不足1秒。相较于此前最先进的方法,SHARP将3D生成所需时间缩短至千分之一。更关键的是,所生成的3D模型可在消费级GPU上实现每秒超100帧的渲染速度,同时输出高分辨率、照片级真实的邻近视角图像。基于物理尺度,实现精准视角控制不同于多数仅关注视觉效果的3D重建方案,SHARP生成的3D表示建立在以米为单位的绝对尺度之上。这意味着用户在虚拟环境中移动视角时,其位移量能与现实世界中的相机运动精确对应,极大提升了交互的真实感与可用性。研究团队在包括Unsplash、ETH3D和Middlebury在内的多个公开数据集上进行了广泛测试,验证了SHARP在不同场景、光照和内容类型下的高泛化能力与鲁棒性。画质指标全面领先,细节还原能力突出在客观画质评估方面,SHARP表现同样亮眼:在LPIPS感知相似度指标上,相较当前最优模型提升25%–34%;在DISTS图像失真度量上,误差降低21%–43%。更重要的是,该方法能在保持几何结构完整性的同时,精准还原输入图像中的细微纹理与锐利边缘,使合成结果在视觉上几乎难以与原始照片区分。目前,相关论文已在arXiv公开,项目代码也已开源至GitHub。Apple研究团队表示,SHARP有望成为单图像高质量3D生成的新标准,为AR、内容创作、机器人视觉等领域带来深远影响。Apple Github:https://apple.github.io/ml-sharp/
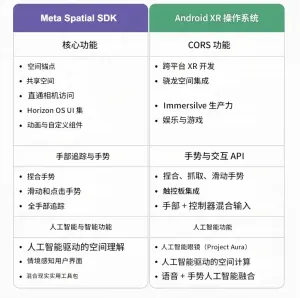
随着虚拟现实、增强现实及混合现实技术的融合趋势日益明显,XR生态系统正迎来新一轮竞争高潮。一边是Meta推出的SpatialSDK/HorizonOS,旨在简化Quest设备上的开发流程;另一边则是由Google联合三星和高通共同打造的AndroidXROS,力图成为开放标准的空间计算操作系统。两者虽都致力于推动XR开发的普及化,但其背后的产品理念却截然不同。MetaSpatialSDK/HorizonOS:简化引擎依赖,加速原生开发Meta的SpatialSDK允许开发者使用Android原生工具(如Kotlin、AndroidStudio及相关库)直接为Quest系列设备构建XR应用,无需依赖重型游戏引擎。核心功能:空间锚点:在物理世界中固定虚拟对象;共享空间:支持多人协作与社交互动;透视相机:将现实环境无缝融入虚拟体验;HorizonOSUI组件:提供统一的用户界面设计元素;MR实用套件:辅助开发MR场景下的交互逻辑。手势识别:支持捏合、滑动、点击等基础手势,以及完整的手部追踪能力。AI功能:上下文感知UI:基于环境理解自动调整界面布局;AI驱动的空间认知:提升场景理解和物体识别精度;自适应MR混合:根据不同光照条件动态优化虚实叠加效果。最佳适用人群:适用于已深度嵌入Meta生态圈的开发者,特别是那些希望摆脱传统游戏引擎束缚,探索轻量化XR工作流的专业人士。开发者资源链接:MetaSpatialSDK示例代码(GitHub)MetaHorizonOS开发者资源AndroidXROS:跨平台兼容,拥抱开放生态由Google主导、三星与高通共同参与的AndroidXROS是三星GalaxyXR头显及ProjectAuraAI眼镜背后的动力源泉,定位为一个面向多终端的开放式空间计算平台。核心功能:跨平台XR开发:确保应用能在不同硬件上流畅运行;SnapdragonSpaces集成:利用高通芯片组的强大算力;沉浸式生产力与娱乐:覆盖从办公到游戏的全方位应用场景。手势识别:提供捏合、抓取、滑动等复杂手势支持,并兼容触控板输入及手柄操作。AI功能:AI眼镜(ProjectAura):集成语音+手势的多模态输入方式;AI驱动的空间计算:通过智能算法优化用户体验。最佳适用人群:适合追求开放架构、企业级XR解决方案及AI增强体验的开发者群体。开发者资源链接:AndroidXR官方开发者页面AndroidXRSDK开发者预览博客FramesixtyAndroidXR开发指南这场XR平台之争,不仅是技术层面的竞争,更是对未来人机交互模式话语权的争夺。无论是Meta的封闭生态还是Google的开放联盟,都将深刻影响下一代空间计算产品的走向与发展路径。对于开发者而言,选择哪条道路,或许意味着不同的创新机遇与市场前景。特征区域MetaSpatialSDK/HorizonOSAndroidXR操作系统核心能力空间锚点、共享空间、透视、地平线用户界面跨平台XR、骁龙空间、生产力、游戏手势捏合、滑动、点击、全手追踪捏合、抓取、滑动、触控板、混合输入人工智能功能情境感知用户界面、AI空间锚点、混合现实实用工具包人工智能眼镜、多模态输入、人工智能驱动的空间计算生态系统契合度MetaQuest设备,HorizonOS三星GalaxyXR、ProjectAura、开放式 AndroidXR
STYLY近日宣布,面向创意机构与制作公司,正式启动一项基于Unity的开源项目,旨在支持Location-BasedEntertainment(LBE,即"基于位置的沉浸式娱乐")内容的开发。该项目的核心目标,是通过降低XR沉浸式内容开发中的技术门槛,让创作者能将更多精力聚焦于创意本身,从而推动高质量LBE体验生态的形成。为此,STYLY将提供一套专为多设备同步场景设计的通信功能模块。在典型的LBE场景中,往往需要数十台头显设备同时运行并保持高度同步。新推出的解决方案可支持最多50台XR设备轻量、高速地协同工作,并兼容主流厂商的头戴式显示器。无论是集成到现有项目,还是用于全新内容开发,流程都更为简便高效。开源授权,商用无忧此次发布的SDK套件采用ApacheLicense2.0或MIT许可证,无论企业或个人、商用或非商用用途,均可免费使用。STYLY还计划面向商场、主题乐园等商业场所的LBE运营方,推出基于该SDK优化的专用运营管理软件服务,进一步完善从开发到落地的全链路支持。值得注意的是,该开源项目与STYLY现有的无代码XR创作与分发平台互不兼容--所提供的SDK无法用于向当前上线的STYLY应用发布内容。STYLY此前已成功推出如VR体验《THEMOONCRUISE》(模拟未来太空旅行)等代表性LBE项目。依托这些一线实践积累,公司希望借由此次开源举措,加速XR技术在实体娱乐场景中的普及,并为下一代沉浸式娱乐形态提供基础设施支持。开源仓库:https://github.com/styly-dev/
本周,腾讯正式面向全球推出其Hunyuan3D创作引擎--一款由人工智能驱动的3D内容生成平台,旨在为创作者与企业大幅简化高质量3D资产的生产流程。该平台支持用户通过文本描述、图像或手绘草图直接生成3D模型,相较传统建模方式显著缩短制作周期。腾讯表示,此举意在降低3D内容创作门槛,推动游戏、电商、影视特效等多个行业的数字内容生产效率升级。API开放接入,赋能全球企业工作流目前,Hunyuan3DModelAPI已通过腾讯云向全球企业开放。开发者可将这一3D生成能力无缝集成至自身业务系统中。官方指出,该API适用于游戏开发、电子商务商品展示、电影特效、广告创意、社交媒体内容生成以及3D打印等多个应用场景。为鼓励早期采用,普通用户每日可享受20次免费生成额度;而通过腾讯云接入的企业用户,则将获得200点免费积分用于3D资产生成。开源社区反响热烈,版本持续迭代自2024年11月首次开源以来,Hunyuan3D模型已在AI社区平台HuggingFace上累计获得超300万次下载。该系列已历经多次迭代,最新发布的Hunyuan3D3.0聚焦于高保真物体资产的生成质量。此外,腾讯还推出了专用子模型,例如Hunyuan3DWorld,专为构建大规模交互式虚拟环境设计,适用于游戏、VR及数字内容生态。据腾讯透露,目前已有超过150家企业通过腾讯云接入Hunyuan3D模型,合作方包括Unity中国、BambuLab,以及国内最大的AI内容创作平台Liblib。
曾为WebAR开发树立标杆的平台8thWall日前宣布将逐步终止服务。该平台自2018年上线以来,凭借其基于浏览器的交互式XR应用开发能力,支持在移动端、桌面端及XR设备上无缝部署,成为行业广泛应用的工具。8thWall最初由同名初创公司于2016年创立,并于2022年被知名AR游戏公司Niantic(现更名为NianticSpatial)收购。即便在并购之后,平台仍持续更新,并与Niantic推出的LightshipVPS等空间定位技术深度集成,维持了较强的技术生命力。服务关停时间表明确,用户需提前规划迁移根据官方公告,8thWall的服务将分阶段关闭。2026年2月28日起,平台将停止所有访问权限,届时用户将无法创建新账户、登录系统,也无法新建或编辑项目,更不能导出资产和项目数据。不过,在2026年2月28日至2027年2月28日这一整年间,已发布或托管的项目仍可正常访问和运行,为开发者保留了一年的缓冲期以安排替代方案。最终,2027年2月28日之后,平台的托管服务将彻底终止,所有剩余项目数据将依据数据保留政策予以删除。官方表示,将在此期间提供必要的数据导出窗口,建议用户尽早备份关键内容。开源化尝试:为生态留下火种值得注意的是,8thWall团队正积极推进平台核心组件的开源工作,旨在通过开放代码的方式,保障开发者社区在服务终止后仍能延续部分功能。此举也被视为对WebAR生态的一种责任性收尾,力求实现透明、有序的技术过渡。
WorldLabs与HTC联合发布了面向虚拟制片平台VIVEMars的全新AI工具--AI世界构建器Marble。该工具主打"极简创作",用户仅需输入一张图片或一段简短文字,即可在数分钟内自动生成可用于实拍合成的高保真虚拟场景,大幅降低虚拟制片的技术门槛。空间智能驱动:从文本/图像到3D场景的一键生成WorldLabs是一家专注于"空间智能"(SpatialIntelligence)的初创企业,致力于构建能理解并生成三维世界的基座模型。其首款产品Marble正是这一理念的落地成果:通过名为"AIGaussianSplatting"的生成技术,系统可直接从单张图像或自然语言描述中重建出细节丰富的3D虚拟环境,无需传统建模、UV展开或复杂光照设置等繁琐流程。相比依赖专业3D软件或游戏引擎的工作流,Marble将整个场景构建过程压缩至几分钟内完成,且输出格式轻量,便于实时渲染调用。无缝接入VIVEMarsNova,实现即插即用的虚拟制片HTC的VIVEMars是一套基于VIVEVR硬件生态打造的高性价比虚拟制片系统,利用现有VIVE追踪设备实现精准相机定位。新推出的配套软件VIVEMarsNova已原生支持Marble输出的轻量化PLY格式数据,并与VIVEMarsCamTrack相机追踪模块深度集成。用户只需将Marble生成的场景导入Nova,连接普通摄像机,即可在绿幕前实时合成实拍画面与AI生成的虚拟背景。整个流程无需UnrealEngine、编程经验或高级3D工具知识,真正实现"所想即所得"的影视级合成效果。这一整合方案显著缩短了从创意到成片的制作链路,使独立创作者、小型工作室甚至非技术背景的内容生产者也能快速拓展视觉表达边界,在短视频、广告、直播乃至教育内容等领域释放新的创作潜力。
VR52网成立于2015年,平台提供VR头显、AR眼镜、配件外设、厂商、测评、行业资讯、游戏与应用、展会活动等。