繁
自动驾驶技术公司Waymo近日宣布推出WaymoWorldModel--一款基于生成式人工智能的大型3D仿真系统,专为训练和验证其核心自动驾驶系统"WaymoDriver"而设计。该模型不仅可复现日常交通场景,还能生成现实中极为罕见甚至从未发生过的极端情境,从暴雨洪水到野生动物闯入道路,全面提升自动驾驶系统的泛化与安全能力。基于GoogleDeepMindGenie3,实现多模态高保真仿真Waymo表示,该世界模型建立在GoogleDeepMind开发的通用世界模型Genie3基础之上。Genie3通过在海量、多样化的视频数据上进行预训练,已具备对物理世界运行规律的深层理解。Waymo在此基础上针对驾驶场景进行领域适配,输出高度逼真的多传感器数据,包括摄像头图像与激光雷达(LiDAR)点云,甚至能生成包含时间维度的4D点云,提供精确的深度与运动信息。与行业主流做法不同--即仅依赖车队实际采集的道路数据从头训练仿真模型--WaymoWorldModel借助Genie3的"世界知识",突破了真实数据的局限。这意味着系统不仅能学习已发生的驾驶经验,还能"想象"并模拟从未被记录的长尾场景:比如一头大象突然出现在城市街道,或山体滑坡阻断高速公路。三大控制机制,实现灵活、可控的虚拟测试为确保仿真的实用性与可操作性,WaymoWorldModel提供了三种核心控制方式:驾驶动作控制:仿真环境能实时响应特定的车辆控制指令,实现闭环测试;场景布局控制:用户可自定义道路结构、信号灯状态及其他交通参与者的行为逻辑;语言控制:最灵活的交互方式,仅需自然语言指令即可调整昼夜、天气,甚至生成完全合成的虚构场景(如"午夜暴雨中的施工区")。更值得注意的是,该模型还能将普通手机或行车记录仪拍摄的任意视频,自动转化为多模态仿真环境。这使得Waymo能在真实地点的数字孪生中测试其Driver系统,既保留了现实世界的细节真实性,又赋予其可控的测试条件。构建更严苛的安全基准,提前应对未知挑战Waymo强调,通过将自动驾驶系统置于这些高度复杂、动态且多样化的虚拟世界中,公司得以建立比现实路测更严格、更全面的安全验证基准。在真正遭遇极端事件前,系统已在数字空间中"经历"过成千上万次类似挑战,从而显著提升其在现实世界中的鲁棒性与可靠性。这一技术标志着自动驾驶研发正从"数据驱动"迈向"知识+生成驱动"的新阶段--不再被动等待罕见事件发生,而是主动创造、学习并征服它们。
2025年8月,谷歌旗下AI研究实验室DeepMind发布了Genie3,展示了一套能够实时生成交互式虚拟环境的AI系统。如今,谷歌正式向部分用户开放该技术的实验性原型--GoogleAI订阅用户即可通过网页界面亲自体验。虽然目前尚不能"即时生成完整VR世界",但这一进展已让梦想中的"AI游戏引擎"轮廓初现。双提示输入+实时编辑,迈向生成式虚拟空间Google将ProjectGenie定义为"实验性研究原型",并非成熟的消费级产品。其核心功能是让用户通过网页界面创建、探索并修改交互式虚拟环境。与常见的图像或视频生成模型类似,Genie也依赖文本提示和/或参考图片作为输入。但它的设计更进一步:系统提供两个主要提示框--一个用于描述整体环境(如"中世纪城堡庭院"),另一个用于定义角色(如"持剑骑士")。此外,还有一个辅助提示框允许用户在最终生成前微调细节,例如"把剑变大"或"将树木改为秋季状态"。当前仍处早期阶段,功能与物理逻辑均有局限据谷歌官方博客说明,作为早期研究系统,ProjectGenie存在多项限制:生成的环境可能无法严格遵循真实物理规律;角色控制响应尚不稳定;单次会话时长限制为60秒;部分此前公布的高级功能尚未上线。目前,用户唯一可导出的内容是一段体验视频,但可以浏览并"混搭"平台画廊中其他用户创建的虚拟世界。该原型现阶段仅面向美国地区年满18岁的GoogleAIUltra订阅用户开放,未来计划逐步扩大可用范围。
只需输入一段文字或一张图片,就能即时生成一个完整、连贯且可自由漫游的3D虚拟空间--这正是AI初创公司SpAItialAI最新推出的生成式模型Echo所实现的能力。该技术不仅大幅降低3D内容创作门槛,更重新定义了人与虚拟空间的交互方式。真正的"空间生成",而非像素拼接Echo背后的核心技术是一种被称为空间基底模型(SpatialFoundationModel,SFM)的新型AI架构。与传统生成模型聚焦于像素不同,SFM直接以物理空间本身为生成对象。它能基于现实世界的物理规律,在米级尺度上预测完整的3D场景结构,确保新视角、深度图及交互结果均源自同一个一致的底层世界模型。这意味着,无论用户从哪个角度观察或如何操作环境,所见内容都具备几何与语义上的一致性,避免了传统方法常见的视角断裂或逻辑矛盾问题。实时交互+低门槛访问,人人皆可创作3DEcho生成的3D世界支持实时相机控制与即时渲染,即使在普通笔记本电脑或低性能设备上,也能通过网页浏览器流畅运行,无需高端显卡或专业VR设备。这种轻量化设计使其覆盖人群从专业设计师延伸至普通消费者。更关键的是,Echo并非"一次性输出"。用户可在生成后对3D场景进行深度编辑:更换材质、增删物体、整体风格重绘等操作均可实现,且系统会自动维持场景的三维一致性,确保修改后的世界依然逻辑自洽、视觉连贯。应用场景广阔,从游戏到机器人仿真凭借上述特性,Echo为多个领域打开了新的工作流可能:数字孪生:快速构建真实环境的可交互复刻;游戏开发:一键生成基础关卡并支持后续迭代;3D设计与建筑可视化:从草图或描述直接进入空间体验;机器人训练:在符合物理规律的合成环境中进行仿真学习。目前,SpAItialAI已在其官网展示多个由Echo生成的示例世界,并开放封闭测试注册通道。用户仅需提供一段文本或单张图像,即可尝试构建属于自己的可编辑3D宇宙。体验申请:https://www.spaitial.ai/join-waitlist
在AI生成3D内容的竞赛中,Meta最新推出的WorldGen系统再次将行业门槛推高--它能仅凭一段文字提示,自动生成几何一致、视觉丰富、可交互导航的三角网格。然而,Meta却坦言:这项技术尚未准备好集成到其社交VR平台HorizonWorlds中。从AssetGen到WorldGen:Meta的AI造世之路早在2025年5月,Meta就预告将在HorizonWorlds创作工具中引入"AI自动生成完整3D世界"的能力,并发布了相关模型AssetGen2.0。6月,该功能被正式命名为"EnvironmentGeneration"(环境生成),并展示了示例场景,称将"很快上线"。结果,8月上线的EnvironmentGeneration仅能生成一种特定风格的岛屿,与"通用世界生成"的愿景相去甚远。如今,Meta在一篇技术论文中正式披露了其更强大的下一代系统--WorldGen,这才是真正面向"任意文本生成任意世界"的终极方案。WorldGen是什么?不是GaussianSplat,而是真·游戏级3D与近期热门的WorldLabs的Marble(基于GaussianSplatting)或GoogleDeepMind的Genie3(生成交互式视频流)不同,WorldGen输出的是标准的三角网格(trimesh):兼容Unity、Unreal等传统游戏引擎;包含完整的导航网格(navmesh),支持角色碰撞检测与NPC自主导航;场景由真实3D资产构成,而非视觉近似体。Meta将其描述为:"一个端到端的先进系统,通过单一文本提示生成可交互、可导航的3D世界,服务于游戏、仿真与沉浸式社交环境。"四步生成流程:从文本到可玩世界据Meta披露,WorldGen的生成流程分为四大阶段:(1)规划阶段(Planning)程序化生成基础布局(blockout)提取导航网格(navmesh)生成参考图像指导后续重建(2)重建阶段(Reconstruction)图像到3D基础模型生成基于navmesh构建完整场景结构初步纹理生成(3)分解阶段(Decomposition)使用加速版AutoPartGen提取场景部件(如门、窗、家具)对部件数据进行清洗与结构化(4)精修阶段(Refinement)图像增强网格细节优化高质量纹理贴图生成整个过程融合了程序化生成、扩散模型、场景理解与几何优化,形成一条完整的AI世界生产管线。为何还不上线?两大瓶颈待解尽管技术惊艳,Meta明确表示WorldGen暂不会集成到当前的HorizonWorldsDesktopEditor,也不会作为即将推出的HorizonStudio的首发功能。原因有二:空间尺寸受限:目前仅能生成50×50米的区域,对于开放世界而言太小;生成速度慢:从文本到完整世界仍需较长时间,无法满足创作者"秒级迭代"需求。Meta正在全力优化这两点,目标是在2026年推出大幅升级版,以兑现其在Connect2025大会上展示的HorizonStudio愿景--一个拥有AI助手的全能创作平台,可即时生成:完整世界定制化资产具备行为逻辑的NPC特定玩法机制⚠️但当时演示的内容,可能更多是"概念原型",而非已部署的技术。HorizonWorlds创作现状:DesktopEditor已支持部分AI功能目前,创作者可通过HorizonWorldsDesktopEditor进行flatscreen开发:导入3D模型、贴图、音频;使用TypeScript编写游戏逻辑;在美国、英国、加拿大、欧盟、澳大利亚、新西兰等地区,还可调用AI生成:3D网格资产纹理与天空盒音效与环境音TypeScript代码片段但完整世界生成,仍需等待WorldGen成熟。展望随着AI3D生成技术指数级演进,Meta很可能在2026年实现其"人人都是世界建筑师"的承诺。届时,HorizonStudio或将成为首个真正意义上的AI驱动元宇宙创作平台--你只需说:"创建一个赛博朋克夜市,有霓虹招牌、雨天街道、可互动的机器人摊贩",系统便在几分钟内交付一个可多人游玩的完整VR世界。而WorldGen,正是通往这一未来的基石。
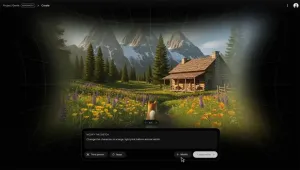
由人工智能先驱李飞飞(Fei-FeiLi)于去年创立的初创公司WorldLabs,近日推出其首款产品--Marble。这款生成式AI模型能将单张图片、一段文字,甚至短视频,在短短几分钟内转化为可在WebXR中直接浏览的体素化3D场景,为VR/AR内容创作带来前所未有的效率革命。从ImageNet到"世界模型":李飞飞的新征程作为2010年代推动计算机视觉爆发的关键人物,李飞飞因创建ImageNet数据集而广为人知--她敏锐地意识到:高质量标注数据的缺失,才是AI进步的最大瓶颈。如今,她将这一理念延伸至三维空间,带领WorldLabs打造所谓"首类生成式多模态世界模型"(first-in-classgenerativemultimodalworldmodel)。Marble的核心技术基于近年主流的3DGaussianSplatting(高斯泼溅)技术--通过在三维空间中排布成千上万个半透明彩色"高斯点",实现实时、任意视角的逼真渲染。但与其他系统相比,Marble在输入灵活性与生成速度上实现了显著突破。单图秒变3D?Marble的能力边界免费模式:仅需一张图片或一段文本提示,几分钟内即可生成可浏览的3D场景;付费订阅(20美元/月):支持多图输入、短视频、甚至粗略3D结构,并通过名为Chisel的编辑工具进行深度创作。Chisel允许用户像使用游戏引擎一样,在场景中放置简单几何体(如立方体、球体),再用自然语言指令(如"把这里变成热带雨林")将其转化为细节丰富的体素环境。更关键的是,付费用户还能:对生成场景进行交互式编辑与扩展;合并多个世界构建复杂空间;导出为传统3D网格(mesh),用于Unity、Unreal等引擎开发(转换需数小时)。所有生成内容均可通过WebXR在Quest3、AppleVisionPro等设备的浏览器中直接查看,无需安装专用应用。实测体验:快,但仍有局限在实际测试中(例如将一张2014年SteamDevDaysVR会场照片输入Marble),生成场景的质量明显低于Meta的HorizonHyperscape或VarjoTeleport,大致介于NianticScaniverse之上、专业扫描之下。主要问题在于:画面中心区域(对应原图内容)细节尚可;边缘及背面区域则依赖AI"脑补",出现典型高斯泼溅的模糊、扭曲或结构失真;若仅用单图输入,相机视野外的内容纯属幻觉,与真实环境可能大相径庭。📌因此,若追求高保真重建,仍需提供多角度图像或视频。为何Marble依然值得期待?尽管存在画质限制,Marble的真正价值在于"快速原型+语义驱动创作":游戏开发者可用它几分钟内搭建关卡雏形;教育者能将历史照片转为可探索的3D课堂;社交VR创作者可通过自然语言"描述梦境",即时生成虚拟聚会空间。结合Chisel的几何可控性与自然语言接口,Marble正在模糊"内容消费者"与"世界建造者"之间的界限。使用须知官网地址:marble.worldlabs.ai免费账户生成的场景默认公开;私有场景、高级编辑与导出功能需订阅20美元/月计划。
由道格·里曼(DougLiman)、JulinaTatlock与JedWeintrob联合执导,30Ninjas(代表作《DinoHab》)开发的180度XR短片《Asteroid》,将成为三星即将推出的AndroidXR头显的首发体验内容之一。这部高风险动作惊悚片专为新设备打造,集结了朗·普尔曼(RonPerlman)、海莉·斯坦菲尔德(HaileeSteinfeld)、LeonMandel以及NFL球星DK·梅特卡夫(DKMetcalf)等明星,讲述一群陌生人驾驶老旧火箭前往近地小行星采矿、追逐巨额财富的故事。三段式体验:从AI对话到叙事崩塌《Asteroid》分为三个部分,开篇即是一场与"AI版DK·梅特卡夫"的生成式AI对话。尽管开发者设置了系统级防护机制,防止用户进行不当提问(Tatlock透露,AI会在越界时介入劝阻),但这场互动本身却成为体验的"第一道坎"。对于不熟悉NFL的观众(如笔者本人)而言,面对一个陌生的虚拟名人,强行开启对话显得极为尴尬。更关键的是,AI的回应虽具一定动态性,但语调与情境时常脱节,破坏了本就薄弱的叙事沉浸感。即便忽略生成式AI在伦理与版权上的争议,其在严肃叙事中的应用仍显得生硬且不成熟。15分钟高潮:电影质感,叙事平庸真正的影片部分约15分钟,采用180度全景拍摄,cinematography精良,制作水准媲美院线大片,充分展现谷歌对该项目的资源投入。故事回归经典的"贪婪反噬"主题,Steinfeld的表演尤为亮眼,饰演一名隐藏真相的飞船船员,为线性叙事增添张力。然而,受限于时长,多数角色缺乏深度塑造。尽管视觉呈现出色,但剧情本身并无新意,难以让观众真正投入情感。探索终章:侦探游戏?还是AI的"翻车现场"?第三部分转为探索式互动:玩家需在陨石着陆点寻找仍存活的梅特卡夫角色,通过手部追踪拾取物品、触发传送,并向其提问以揭开真相。机制设计颇具巧思,接近轻量级侦探游戏。但问题再次出在生成式AI的对话系统。提问后,AI角色的回应常显得不合逻辑或情绪错位,严重削弱了悬疑氛围与世界观一致性。正如《StellarCafe》的体验者所反馈的"烦躁感",在叙事驱动的严肃作品中,不可预测的AI回应反而成了沉浸感的破坏者。首发亮点,但AI互动尚不成熟作为三星AndroidXR头显的launchtitle,《Asteroid》在电影级制作、视觉呈现与空间设计上展现了顶级水准,证明谷歌与三星正以高规格内容推动XR叙事进化。然而,其对生成式AI的尝试,却暴露了当前技术在叙事一致性、情感共鸣与角色可信度上的明显短板。它提醒我们:互动性不等于沉浸感。尤其是在短篇、高强度的叙事体验中,精心编排的脚本往往比"看似自由"的AI对话更有效。《Asteroid》将于今年晚些时候,随三星AndroidXR头显正式发布。它是一次值得尊敬的探索,但也是一记清晰的警示:AI驱动的角色互动,尚未准备好承担严肃叙事的重任。
当AI生成内容从"观看"走向"进入",我们距离科幻电影中的沉浸式虚拟世界还有多远?谷歌旗下AI研究实验室DeepMind近日发布了其新一代生成式AI模型--Genie3,一个能够根据简单文本提示,实时生成可交互、可导航虚拟环境的系统。这一进展,被外界视为向《星际迷航》中"全息甲板"(Holodeck)概念迈进的又一里程碑。从"生成视频"到"生成世界":一次范式跃迁与当前主流的生成式AI不同,Genie3并不生成一段预渲染的静态视频,而是在运行时逐帧生成动态环境,支持用户实时交互与环境反馈。这意味着,用户不再是被动观看者,而是可以"进入"并影响AI所构建的世界。据DeepMind介绍,Genie3能够在普通显示器上以720p分辨率、24帧/秒的性能运行。尽管目前仅支持平面屏幕,尚未适配VR头显(如Quest3的双目2K+分辨率、90Hz刷新率需求),但其架构已展现出向高沉浸设备迁移的潜力。更关键的是,这些生成的虚拟场景能在数分钟内保持视觉与物理一致性。系统具备某种形式的"短期记忆",能记住用户此前的操作并反映在后续环境中--这是迈向持久化虚拟世界的重要一步。可编程的虚拟宇宙:从江户时代到阿姆斯特丹运河Genie3的能力边界极为广泛,可模拟:自然景观(如森林、沙漠、极地)历史场景(如1800年的Osaka)虚构世界(如动画风格城市)动态事件系统:用户可通过文本指令触发"世界事件",例如"下雨"、"出现一辆红色跑车"或"天空飞过恐龙"这种"可提示化世界事件"(promptableworldevents)机制,赋予用户近乎上帝模式的控制力。你不仅能在阿姆斯特丹的运河上召唤一辆摩托艇,还能瞬间将天气从晴朗转为暴风雨。不只是娱乐:为具身AI提供训练场尽管Genie3的娱乐潜力显而易见,但DeepMind强调其更深层使命:作为具身AI(EmbodiedAI)的训练平台。在机器人、游戏AI和通用人工智能(AGI)研究中,AI代理(Agents)需要在复杂、动态的环境中学习决策、执行动作并适应变化。Genie3提供了一个低成本、高灵活性的虚拟沙盒,可用于:训练机器人在不同地形中导航模拟多智能体协作与竞争探索AI在开放世界中的长期行为演化不过,DeepMind也坦承当前局限:限制领域具体挑战代理动作空间当前AI代理可执行的动作种类有限,复杂行为难以建模多代理交互在共享环境中,多个AI代理的协同与竞争模拟仍不成熟地理精确性难以完美还原真实世界地理位置与建筑细节文本渲染画面中的文字生成仍模糊不清,影响信息传达长期稳定性环境一致性通常只能维持几分钟,难以支持长时间任务通往Holodeck的阶梯尽管Genie3还远未达到"全息甲板"级别的沉浸感与物理真实,但它标志着生成式AI正从"内容生成"向"世界生成"演进。未来,当此类技术与VR/AR、物理引擎、神经渲染深度融合,我们或许真能实现:一键进入任何历史时刻实时构建可交互的游戏关卡为AI提供无限训练场景正如WillSmith吃意大利面的魔性视频曾震惊网络,Genie3预示着:下一个阶段,这些"荒诞模拟"将不再只是可看的,而是可进、可改、可玩的。